这是一个声音克隆AI,建议3060以上N卡~~严格按照我的教程做,测试成功!
下载地址:
https://www.lvruan.com/app/560702
进入百度网盘下载,太大了,没办法~~
目录结构
1,下载后,把文件解压到D盘的AI目录下,解压后,AI目录下有个GPT_SoVITS文件夹就是对的;
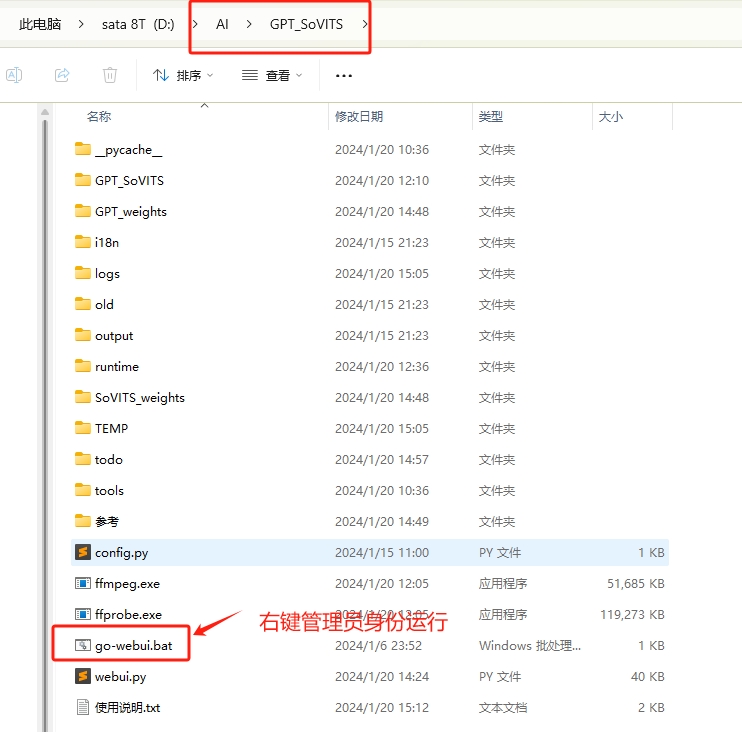
2,进入GPT_SoVITS文件夹,运行go-webui.bat开始用;
去背景声
3,自动进入http://localhost:9874/
勾选:是否开启UVR5-WebUI
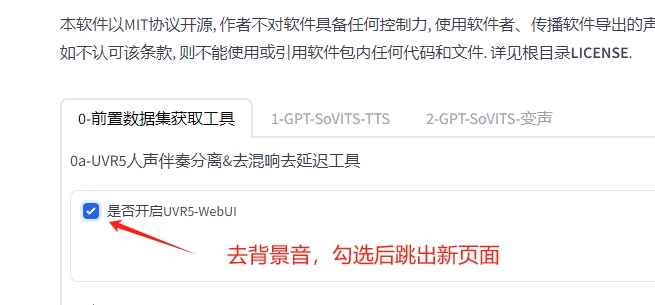
跳出新页面http://localhost:9873/
拿到你要克隆的音频,最好是wav格式,放到ToDo目录里,不要留其他人的声音
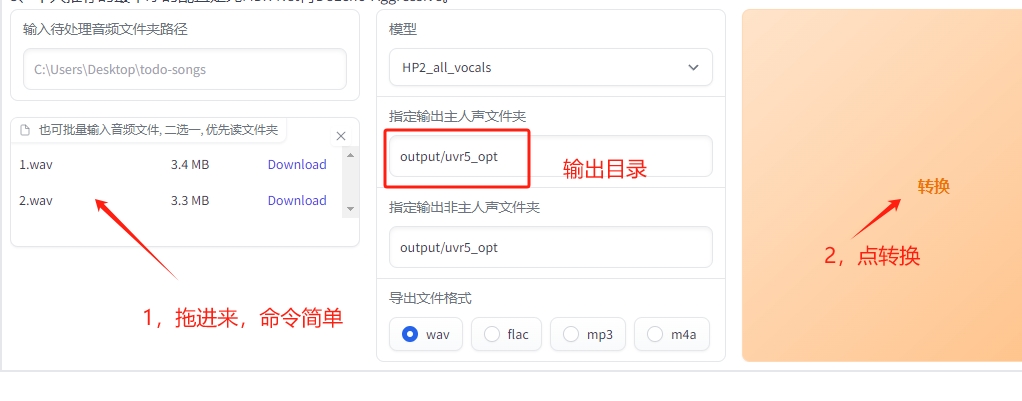
也可以直接把音频拖进去~~~但是上面的文件夹路径要删空
- 6,点击 “转换” 分离人声和背景声;
- 7,在D:\AI\GPT_SoVITS\output\uvr5_opt 目录找到生成的人声和背景声,把instrument_开头的.flac背景声全部删除掉,留vocal_开头的.flac文件
- 8,回到http://localhost:9874/页面,取消勾选 是否开启UVR5-WebUI
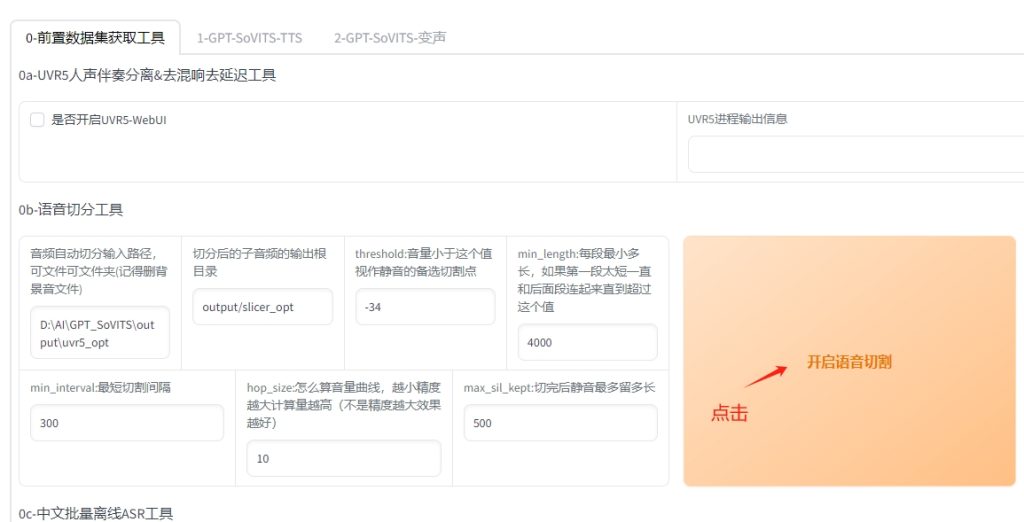
0b-语音切分工具
- 9,开启语音切割
- 10,开启离线批量ASR
打标页面
11,勾选 是否开启打标WebUI 进入打标页面,校对语音和文字,太短太离谱的选中yes,然后delete Audio删除,修改好文字点save file,下页面点Next Index 最后保存。关闭本页面
12,取消勾选 是否开启打标WebUI
1-GPT-SoVITS-TTS
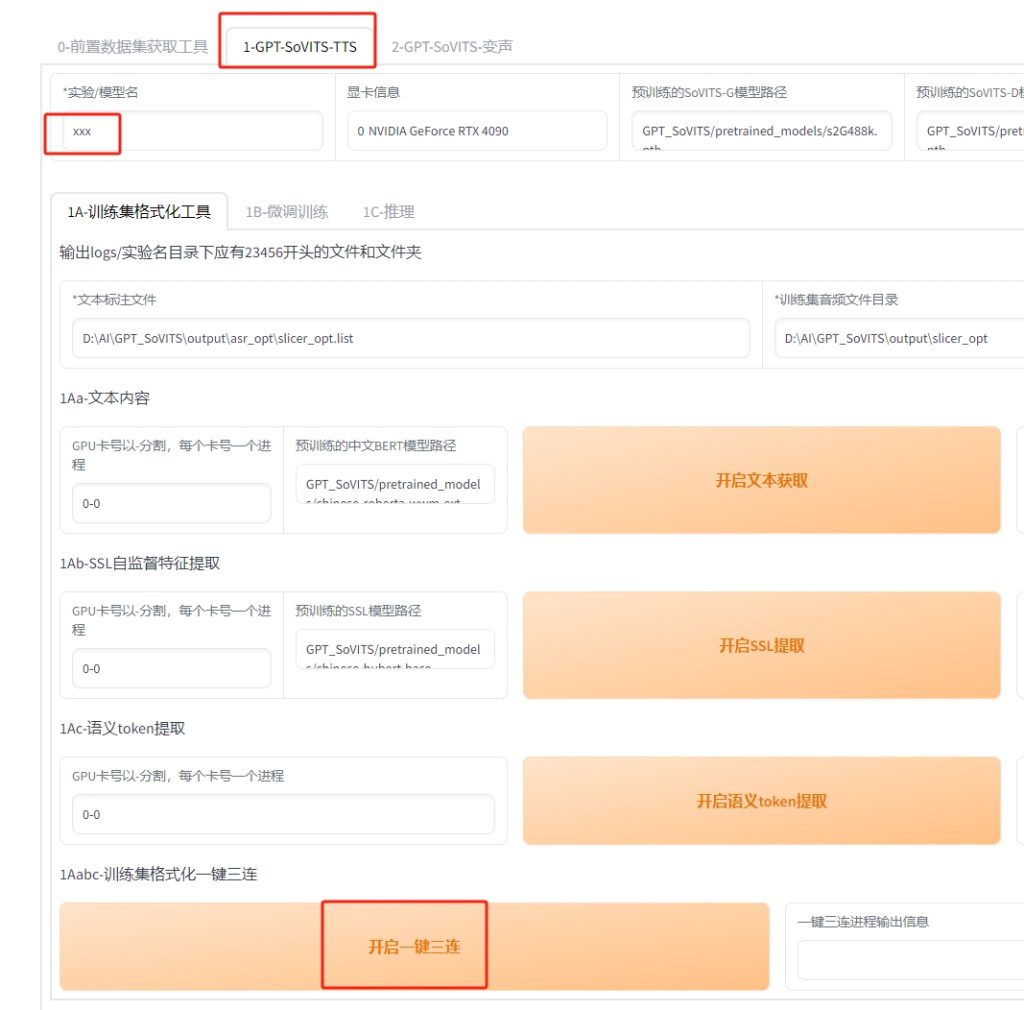
13,点第二个选项:1-GPT-SoVITS-TTS,给实验/模型名起个英文名比如xxx,点最下的 开启一键三连
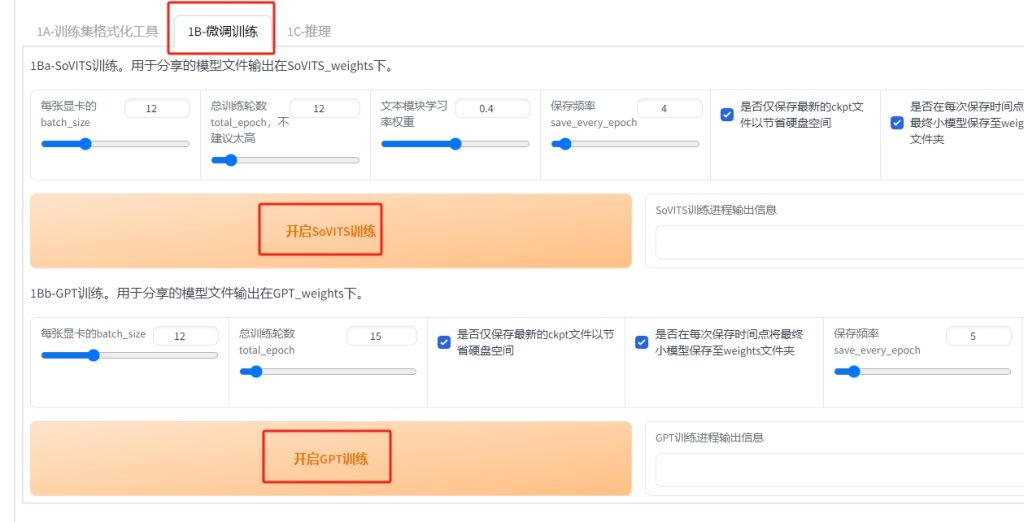
14,点 1B-微调训练 进入训练:开启SoVITS训练,成功后 开启GPT训练 确定要成功!
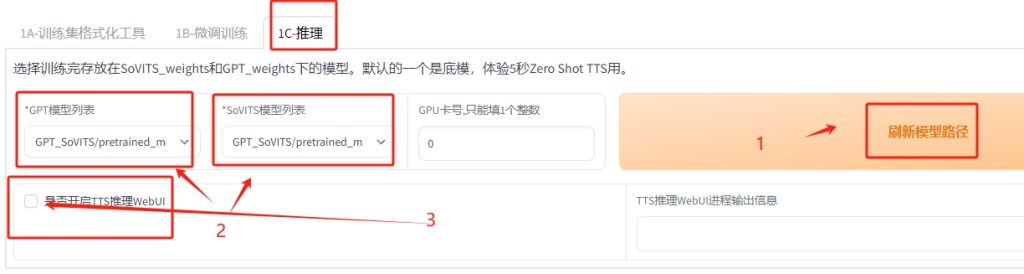
推理
15,点 1C-推理:点 刷新模型路径 ,选GPT模型你刚命名的模型的最大数字,比如e15版,点SoVits模型列表中的e最大数字版本,要对应你训练的名字哦,勾选:是否开启TTS推理WebUI,进入最终生成语音页面
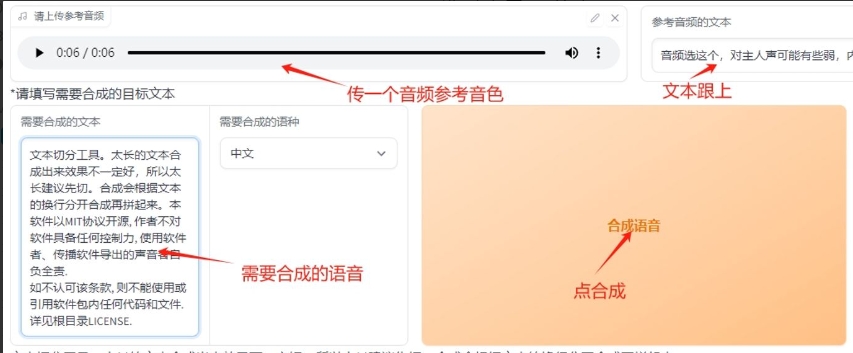
16,把D:\AI\GPT_SoVITS\output\slicer_opt下一个音频作为参考音频,打上对应的文本
17,填入你要合成的文本,合成语音,搞定。






![解决PHPFatalerror: [ionCube Loader]The Loader must appear as the first entry in the php.ini file-绿软市场](https://www.lvruan.com/wp-content/uploads/2024/01/fea34d63d058696-31.jpg)