AniPortrait 是一款先进的人工智能工具,它能够根据音频和一张静态人脸图片自动生成会说话或唱歌的动态视频。这种技术能够产生逼真的人脸动画,并且口型与音频中的声音完美匹配,使得生成的视频看起来像是实际录制的。AniPortrait 支持多种语言,并允许用户进行面部重绘和头部姿势控制,进一步增强了动画的真实感和多样性。
主要功能
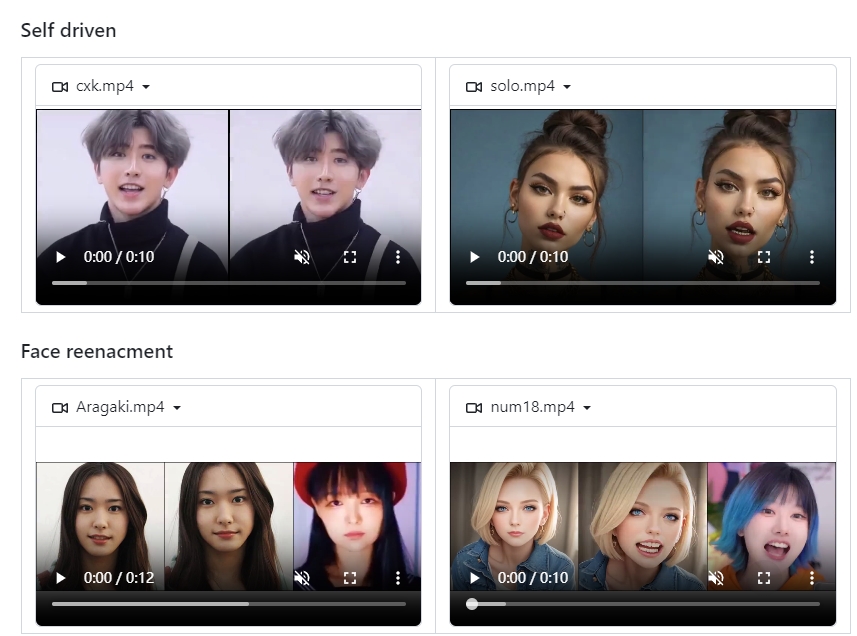
- 音频驱动的动画合成:AniPortrait 能够利用音频文件驱动,根据音频中的语音和声音的节奏动态生成说话或表情变化的肖像动画。
- 面部再现:支持通过分析给定视频中的面部表情和动作,在另一张参考肖像上再现相同的表情和动作,使其复现真人的面部表情和动作。
- 头部姿势控制:用户可以控制生成动画中的头部动作,包括指定头部姿势或选择预设的姿势配置,以达到更自然和多样化的动画效果。
- 自驱动和音频驱动的视频生成:项目不仅支持根据外部音频输入生成动画,还可以进行自驱动的视频生成,即根据预设或随机生成的动作创建动画。
- 高质量动画生成:旨在生成高度逼真的肖像动画,从视觉质量到动作自然度都接近真实人物的外观和表现。
- 灵活的模型和权重配置:提供了一套预训练的模型和权重配置,包括用于去噪、参考生成、姿势指导、动作模块和音频到网格转换的模型,以满足不同用户的需求。
AniPortrait 的这些功能使其成为了创造虚拟角色动画、虚拟主播、个性化视频内容等领域的有力工具。无论是用于娱乐、教育还是市场营销,AniPortrait 都能提供一个新颖且引人入胜的方式来呈现内容。
想了解更多信息或开始使用 AniPortrait,请访问:
AniPortrait 的技术开创性地将音频输入与动态视频输出相结合,开辟了人工智能在视频内容创作领域的新可能。