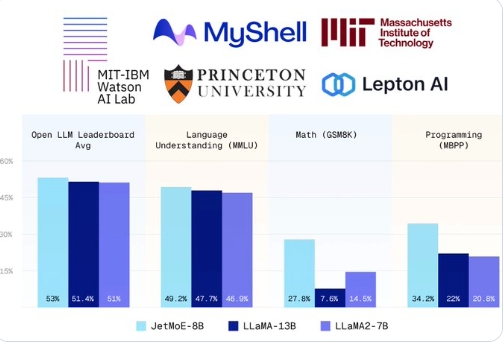
JetMoE-8B 是一款具有高性价比的大规模语言模型,以不到10万美元的训练成本,性能却超越了多个知名模型如 Llama2-7B。
软件功能
- 稀疏激活架构:每个块含两个MoE层,分别是注意力头混合(MoA)和MLP专家混合(MoE),有效降低了计算成本。
- 专家系统:每个MoA和MoE层设有8个专家,每个输入令牌激活2个专家。
- 参数效率高:尽管总参数量高达80亿,但每个输入令牌只激活约22亿参数,显著降低计算需求。
- 完全开源:包括代码和训练过程,全部使用公开数据训练。
软件特点
- 成本效率:在极低的训练成本下提供超越同级竞争对手的性能。
- 计算优化:通过激活部分专家来大幅降低计算需求,优化了性能与资源的平衡。
- 开源透明:提供完全开源的代码和训练过程,促进了技术的透明度和可接入性。
- 竞争性能:在标准化评估中超越LLaMA2-7B等模型,展示了其卓越的技术实力。
应用场景
- 研究和教育:适用于学术研究和教育领域,特别是在自然语言处理和机器学习的教学和实验中。
- 商业智能:企业可利用此模型进行数据分析、客户服务优化和自动化文本处理。
- 技术开发:开发者可以基于这一开源模型开发新的应用程序或服务,推动AI技术的应用创新。
下载地址












