
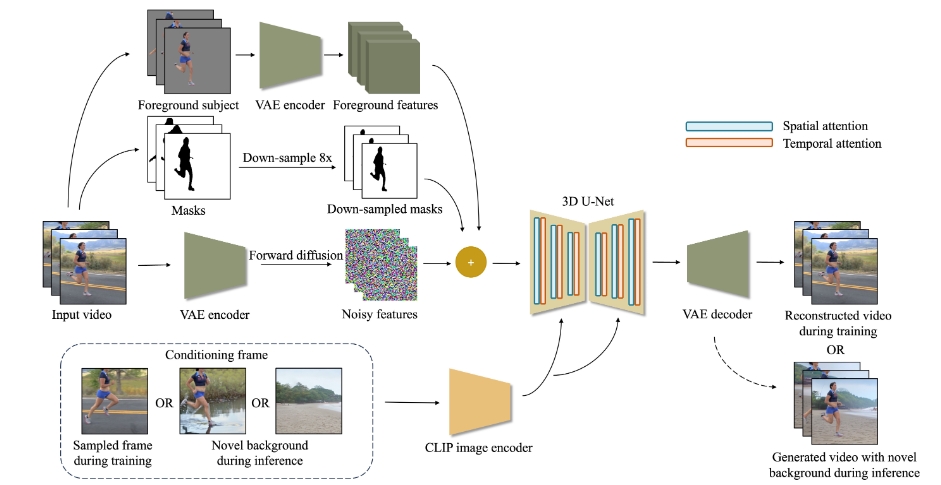
Adobe最近发布了一款名为ActAnywhere的模型,它为视频制作领域带来了创新性的变革。ActAnywhere的主要功能是将原视频中的主体分割出来,并与一张静态图片结合,生成新的视频。这个模型特别注重于保持原视频内容与新背景图片之间的融合度,确保最终视频的真实性和连贯性。
软件功能
- ActAnywhere能够自动完成视频主体分割和背景替换的过程,极大地简化了传统的手工操作。
- 它使用一系列前景主体分割图作为输入,同时以描述所需场景的图片作为条件,创造出既真实又连贯的视频。
- 模型确保前景与背景之间的交互自然,并忠实于设定的条件帧。
软件特点
- ActAnywhere借助了强大的大规模视频扩散模型技术,并专门为视频主体分割和背景更换任务进行了定制。
- 该模型在涵盖丰富的人类与场景互动视频的大型数据集上进行了训练。
- 经过广泛的评估,ActAnywhere显示出了卓越的性能,远超过基准水平。
- 模型还能适应多种不同的、甚至是非常规分布的样本,包括非人类主体。
应用场景
- 视频制作:为视频制作人员提供高效的工具,用于快速更换视频背景,同时保持前景和背景之间的自然交互。
- 内容创作:内容创作者可以利用此模型在视频中创造各种创意背景,提高视频的吸引力和创意性。
- 影视后期制作:在影视制作中,ActAnywhere可以作为一种高效的后期处理工具,用于改变或增强场景背景。
下载地址
项目地址:ActAnywhere官方网站












